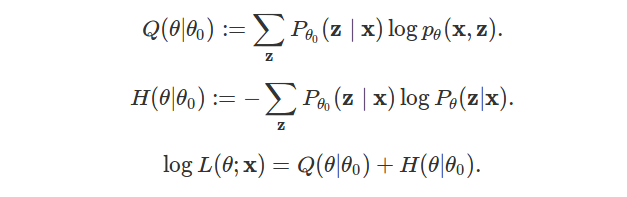This post explains why maximizing likelihood is equivalent to minimizing KL-divergence.
This can already be found here and here, but I restate this in my “own” words.
More generally, I encourage you to read Section 3.13 of Deep Learning book for insights on information theory.
Let \(\mathbf{x} = (x_1, \ldots x_n)\) a dataset of \(n\) elements.
We assume that each \(x_i\) has been sampled independently from a random variable \(X\) with density \(p = p_{\theta_0}\) and corresponding to a true (unknown and fixed) parameter \(\theta_0\).
We let \(q = p_{\theta}\) the density function corresponding to another parameter \(\theta\).
The likelihood of \(\mathbf{x}\) given \(\theta\) is \(L_{\theta}(\mathbf{x}) = \prod_{i = 1}^n p_{\theta}(x_i)\).
The opposite of log-likelihood divided by \(n\) is:
\[-\frac{1}{n} \log L_{\theta}(\mathbf{x}) = -\frac{1}{n} \sum_{i=1}^n \log p_{\theta}(x_i)
\xrightarrow[n \rightarrow +\infty]{} E_{\theta_0} \left[ - \log p_{\theta}(X) \right],\]
and
\[E_{\theta_0} \left[ - \log p_{\theta}(X) \right] = - \int \log p_{\theta}(x) dp_{\theta_0}(x) = - \int \log q(x) dp(x) =: H(p, q).\]
In the previous equation, \(H(p, q)\) stands for the (continuous) cross-entropy between \(p\) and \(q\).
We let \(H(p)\) the (continuous) entropy of \(p\) and \(\text{KL}(p \mid \mid q)\) the Kullback-Leibler divergence between \(p\) and \(q\).
Since \(H(p, q) = H(p) + \text{KL}(p \mid \mid q)\),
maximizing likelihood is equivalent to minimizing KL-divergence.